Data in situ Computation
shortname: COMPUTE
name: Data In Situ Computation
type: Standard
status: Valid
version: 0.1
editor: Aitor Argomaniz <aitor@nevermined.io>
contributors:
Execution of Remote Compute Services using Service Agreements
This SPEC introduces the integration pattern for the usage of Service Execution Agreements (SEA) (also called Service Agreements or Agreements) as contracts between parties interacting in the execution of a Compute Service transaction. This SPEC using the SEA as core element, orchestrates the publishing/execution of this type of compute services.
The intention of this SPEC is to describe the flow and integration pattern independently of the infrastructure Cloud Compute Service. This SPEC MUST be valid for integrating classical infrastructure cloud providers like Amazon EC2 or Azure, but also can be used to integrate other compute providers or On-Premise infrastructure.
It's out of the scope to detail the Service Execution Agreements implementation.
Motivation
The main motivations of this SPEC are:
- Identify the actors involved on the definition and execution of a Nevermined Compute service
- Detail the main characteristics of this interaction
- Specify the pros and cons of this approach
- Identify the API methods exposed via the different libraries
Actors
The different actors interacting in this flow are:
- PROVIDERS - Give access to the Compute Services
- CONSUMERS - Want to make use of the Compute Services
- MARKETPLACES or DOMAINS - Store the DDO/Metadata related with the Assets/services
- INFRASTRUCTURE - Cloud or on-premise infrastructure services providing computing. Typically Amazon, Azure, etc.
Technical components
The following technical components are involved in an end-to-end publishing and consumption flow:
- MARKETPLACE - Exposes a web interface allowing the users to publish and purchase assets and services associated to these assets. It also facilitates the discovery of assets.
- SDK - Software library encapsulating the Nevermined business logic. It's used to interact with all the
components & APIs of the system. It's currently implemented in the following package:
- nevermined-sdk-js - JavaScript version of the Nevermined SDK to be integrated with front-end applications.
- SMART CONTRACTS - Solidity Smart Contracts providing the Service Agreements business logic.
- NODE - Microservice to be executed by PUBLISHERS. It exposes an HTTP REST API permitting access to PUBLISHER assets or additional services such as computation.
- MARKETPLACE-API - Microservice to be executed by MARKETPLACES. Facilitates creating, updating, deleting and searching the asset metadata registered by the PUBLISHERS. This metadata is included as part of a DDO (see DID SPEC and METADATA SPEC) and also includes the services associated with the asset (consumption, computation, etc.).
Flow
This section describes the Asset Compute Service flow in detail. There are some parameters used in this flow:
- DID - See DID SPEC.
- serviceAgreementId - Is the unique ID referring to a Service Execution Agreement established between a PUBLISHER and a CONSUMER. The CONSUMER (via SDK) is the one creating this random unique serviceAgreementId.
- serviceDefinitionId - Identifies one service in the array of services included in the DDO. It is created by the PUBLISHER (via SDK) upon DDO creation and is associated with different services.
- templateId - Identifies a unique Service Agreement template.
Terminology
- Compute Provider - Entity providing a compute service for a price (or for free).
- Compute Service - Service offered by a Compute Provider. It could have different conditions like the type of services, price, etc.
- Workflow - It describes an execution pipeline where you put together input data and an algorithm to process this data and you run using a Compute Service.
Requirements
- A COMPUTE PROVIDER or PROVIDER define the conditions that a Compute service supports. It includes:
- What kind of image (Docker container) can be deployed in the infrastructure
- What are the infrastructure resources available (CPU, memory, storage)
- What is the price of using the infrastructure resources
- A COMPUTE PROVIDER defines a Compute Service in the scope of the Asset (DID/DDO) of the dataset that can be computed
- A CONSUMER defines the task to execute modeling it in a Workflow (including configuration, input, transformations and output)
- A workflow is a new type of Asset. It can be resolvable and be used across multiple independent compute services
- A CONSUMER purchasing a compute service defines which Workflow (DID) is going to execute
- A CONSUMER can purchase a service given by a PROVIDER and execute multiple times till the timeout expires
- A CONSUMER could purchase a service and execute later, the purchase MUST be totally decoupled of execution
- The previous two points could support to buy once a compute service and execute for example the service every night at 3 am
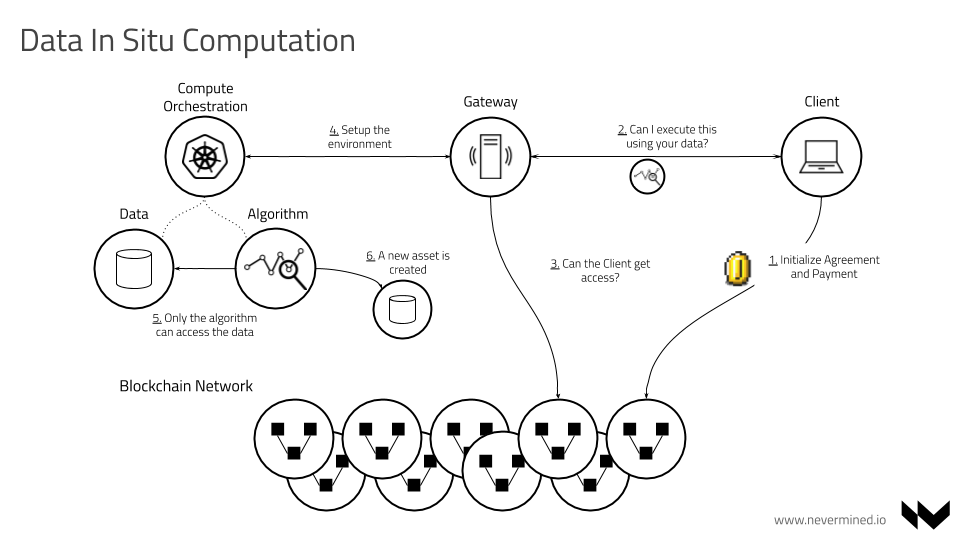
Workflows
From a high-level point of view, a workflow may be considered a view or representation of a real work. A workflow consists of an orchestrated and repeatable pattern of activities transformed into tasks that transform or process information.
In Nevermined, we use the concept of workflow to represent a list of tasks to accomplish with the intention of process data.
From a technical point of view, a workflow is a type of Asset (it takes advantage of all the Nevermined plumbing of registering, metadata publishing, resolving, etc.). The main objective of a workflow is to describe an execution pipeline. A workflow can be split in sequential stages, having each stage an input, transformation (via algorithm) and output.
In the below example, a workflow is modeled in a JSON document with the following characteristics:
- It has a list of sorted stages by the
stages.indexparameter to be executed sequentially - Each stage has a list of minimum requirements, like the image required to support the execution of the algorithm, minimum cpu, memory, etc.
- Each stage has an array of sorted input parameters. Each input parameter may be:
- A DID (example:
"id": "did:nv:12345") - The output of a previous stage (example:
"previousIndexStage": 0)
- A DID (example:
- Each stage has one transformation entry. It includes the id (DID) of the asset in charge of process the input to generate some output
- Each stage includes an entry with some additional output details. This could be a DID or a specific detail about the expected output.
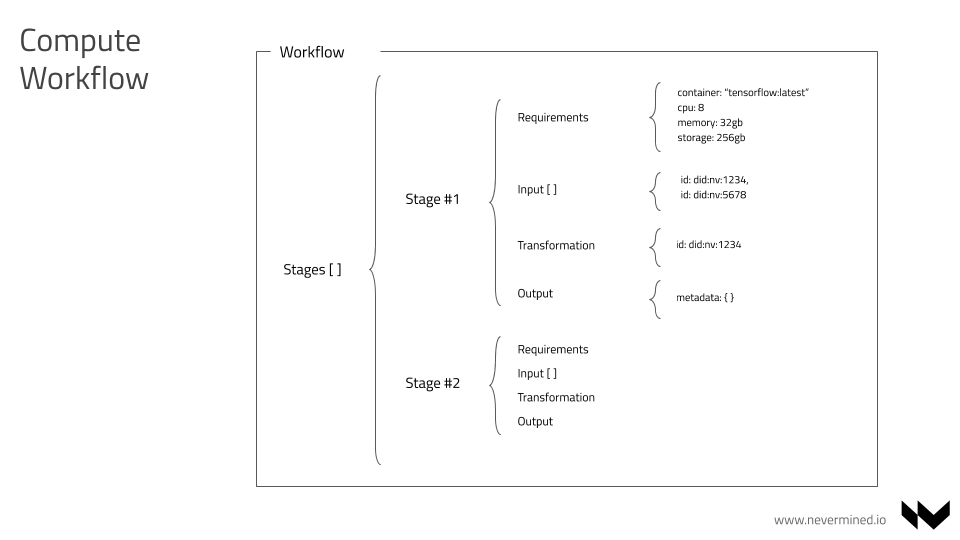
Example of a Workflow:
{
"service": [{
"index": "0",
"type": "metadata",
"serviceEndpoint": "https://service/api/v1/metadata/assets/ddo/did:nv:0ebed8226ada17fde24b6bf2b95d27f8f05fcce09139ff5cec31f6d81a7cd2ea",
"attributes": {
"main": {
"type": "workflow",
"workflow": {
"stages": [{
"index": 0,
"stageType": "Filtering",
"input": [{
"index": 0,
"id": "did:nv:12345"
}, {
"index": 1,
"id": "did:nv:67890"
}],
"transformation": {
"id": "did:nv:abcde"
},
"output": {}
}, {
"index": 1,
"stageType": "Transformation",
"input": [{
"index": 0,
"previousStage": 0
}],
"transformation": {
"id": "did:nv:999999"
},
"output": {}
}]
}
},
"additional": {},
"curation": {}
}
},
{}
]
}
A Workflow is a new type of Asset (a part of datasets, algorithms, etc.).
You can find a complete DDO of type workflow in the ddo-workflow.json example file.
As a new kind of asset, the workflow details will be persisted inside a DDO as part of the "Metadata" service where the type is workflow. An Asset of type workflow, will include in the DDO the following information:
- The Workflow model as part of the
DDO.services["metadata"].main.workflowentity - The rest of the Workflow metadata information (title, author, ect.) as part of the existing Metadata service
A workflow, as every DDO in Nevermined, can be resolved using the Asset Id (DID).
By the time being, the workflow definition supports the execution of sequential stages. It's not supported yet the execution of parallel stages.
Publishing an Asset including Compute Services
The Compute services are published as part of the asset (dataset) metadata as an additional service offered for that specific asset.
The complete flow of publishing an asset with a compute service attached is:
PUBLISHER generates a DID. See How to compute a DID.
PUBLISHER creates a DDO including the following information:
- DID
- Metadata. It contains the asset name, description, etc. For more details see METADATA SPEC.
- Public key of the PUBLISHER
- A list of services (Access, etc). For more details see ACCESS SPEC.
Each service in the list contains certain information depending on its type. Here we document the Compute service. The Access and Metadata services where discussed in the scope of the ACCESS SPEC.
A service of type "compute" contains:
Service Definition ID (
serviceDefinitionId); this helps PUBLISHER find the service definition of a DDO signed by CONSUMERService Agreement Template ID (
templateId); points to an instance of a Service Agreement Template stored by the Template Store Manager. In this case is a template implementing the Compute end to end flowService endpoint (
serviceEndpoint); CONSUMERS signing this service send their signatures to this endpoint to request the execution of a workflowA list of condition keys; condition key is the
keccak256hash of the following:- SLA template ID
- controller contract address (obtained from the solidity contract json file matching the contract name in the SLA condition)
- controller contract function fingerprint (referred to as function signature or selector)
For each condition, a list is required of its parameter values, a timeout, a set of fields determining what conditions depend on other conditions, and a mapping of events emitted by the condition to the off-chain handlers of these events
Each event is identified by name. Each event handler is a function from a whitelisted module
Service Agreement contract address and the event mapping in the same format as the condition events, for off-chain listeners
An integer defining when the agreement is fulfilled in case there are multiple terminal conditions, according to the Service Agreement smart contract
A service of type "compute" contains one endpoint:
serviceEndpoint - A URL to call when the CONSUMER request the execution of a workflow
An example of a complete DDO can be found here. Please do note that the condition's order in the DID document should reflect the same order in on-chain service agreement.
PUBLISHER publishes the DDO in the MARKETPLACE-API. This DDO must include at least one service of type "compute".
here you have an example of the DDO including a Compute service. Below you can find a small fraction of this:
"container":
"service": [{
"type": "compute",
"serviceDefinitionId": "2",
"serviceEndpoint": "http://mynode.org/api/v1/node/services/execute",
"templateId": "804932804923850985093485039850349850439583409583404534231321131a",
"attributes": {
"main": {
"creator": "0x00Bd138aBD70e2F00903268F3Db08f2D25677C9e",
"datePublished": "2019-04-09T19:02:11Z",
"provider": {
"type": "Azure",
"description": "",
"environment": {
"cluster": {
"type": "Kubernetes",
"url": "http://10.0.0.17/xxx"
},
"supportedContainers": [{
"image": "tensorflow/tensorflow",
"tag": "latest",
"checksum": "sha256:cb57ecfa6ebbefd8ffc7f75c0f00e57a7fa739578a429b6f72a0df19315deadc"
}, {
"image": "tensorflow/tensorflow",
"tag": "latest",
"checksum": "sha256:cb57ecfa6ebbefd8ffc7f75c0f00e57a7fa739578a429b6f72a0df19315deadc"
}],
"supportedServers": [{
"serverId": "1",
"serverType": "xlsize",
"price": "5000000000000000000",
"cpu": "16",
"gpu": "0",
"memory": "128gb",
"disk": "160gb",
"maxExecutionTime": 86400
}, {
"containerId": "2",
"typeContainer": "medium",
"price": "1000000000000000000",
"cpu": "2",
"gpu": "0",
"memory": "8gb",
"disk": "80gb",
"maxExecutionTime": 86400
}]
}
},
"serviceAgreementTemplate": {
"contractName": "ServiceExecutionTemplate",
"events": [{
"name": "AgreementCreated",
"actorType": "consumer",
"handler": {
"moduleName": "serviceExecutionTemplate",
"functionName": "fulfillLockPaymentCondition",
"version": "0.1"
}
}],
"fulfillmentOrder": [
"lockPayment.fulfill",
"serviceExecution.fulfill",
"escrowPayment.fulfill"
],
"conditionDependency": {
"lockPayment": [],
"serviceExecution": [],
"releaseReward": [
"lockPayment",
"serviceExecution"
]
},
"conditions": [{
"name": "lockPayment",
"timelock": 0,
"timeout": 0,
"contractName": "LockPaymentCondition",
"functionName": "fulfill",
"parameters": [
{
"name": "_did",
"type": "bytes32",
"value": ""
},
{
"name": "_rewardAddress",
"type": "address",
"value": ""
},
{
"name": "_tokenAddress",
"type": "address",
"value": ""
},
{
"name": "_amounts",
"type": "uint256[]",
"value": []
},
{
"name": "_receivers",
"type": "address[]",
"value": []
}
],
"events": [{
"name": "Fulfilled",
"actorType": "publisher",
"handler": {
"moduleName": "lockPaymentConditon",
"functionName": "fulfillServiceExecutionCondition",
"version": "0.1"
}
}]
},
{
"name": "execCompute",
"timelock": 0,
"timeout": 0,
"contractName": "ComputeExecutionCondition",
"functionName": "fulfill",
"parameters": [{
"name": "_did",
"type": "bytes32",
"value": ""
},
{
"name": "_grantee",
"type": "address",
"value": ""
}
],
"events": [{
"name": "Fulfilled",
"actorType": "publisher",
"handler": {
"moduleName": "execCompute",
"functionName": "fulfillServiceExecutionCondition",
"version": "0.1"
}
},
{
"name": "TimedOut",
"actorType": "consumer",
"handler": {
"moduleName": "execCompute",
"functionName": "fulfillServiceExecutionCondition",
"version": "0.1"
}
}
]
},
{
"name": "escrowPayment",
"timelock": 0,
"timeout": 0,
"contractName": "EscrowPaymentCondition",
"functionName": "fulfill",
"parameters": [
{
"name": "_did",
"type": "bytes32",
"value": ""
},
{
"name": "_amounts",
"type": "uint256[]",
"value": []
},
{
"name": "_receivers",
"type": "address[]",
"value": []
},
{
"name": "_sender",
"type": "address",
"value": ""
},
{
"name": "_tokenAddress",
"type": "address",
"value": ""
},
{
"name": "_lockCondition",
"type": "bytes32",
"value": ""
},
{
"name": "_releaseCondition",
"type": "bytes32",
"value": ""
}
],
"events": [{
"name": "Fulfilled",
"actorType": "publisher",
"handler": {
"moduleName": "escrowPaymentConditon",
"functionName": "verifyRewardTokens",
"version": "0.1"
}
}]
}
]
}
}
}
}]
- PUBLISHER registers the DID, associating the Asset DID to the METADATA API URL that resolves the DID to a DDO.
To do that, the SDK integrates the
DIDRegistrycontract using theregisterAttributemethod.
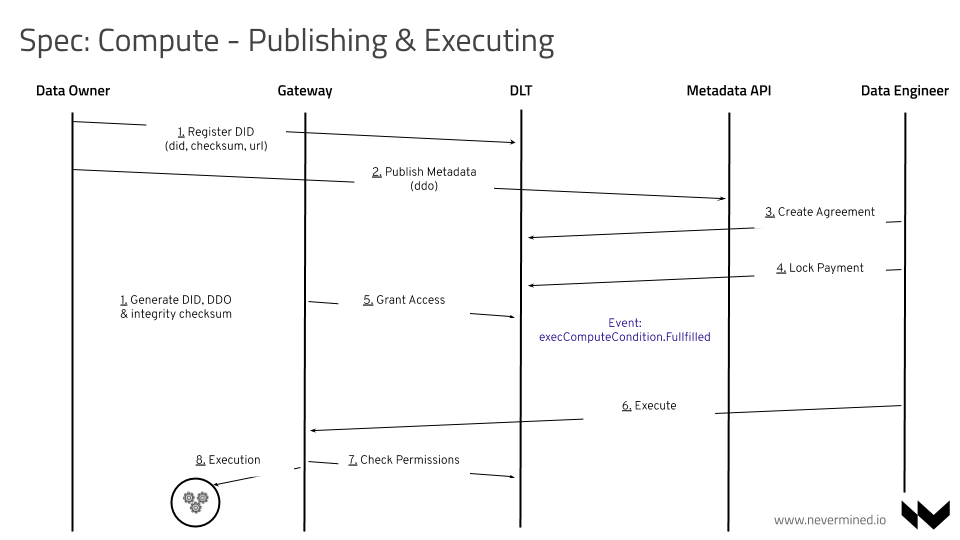
Setting up the Service Execution Agreement
Registering Asset
Using only one SDK call registerAsset(asset_metadata, services_description, publisher_public_key),
the PUBLISHER should be able to register an Asset including a Compute service.
The services_description attribute includes the different services (like compute) associated to this asset.
Consuming Asset
During this phase, through the CONSUMER and the PROVIDER (via NODE) negotiation, the Service Execution Agreement (SEA) is created and initialized.
Using the SDK, a CONSUMER can discover, purchase and use the PROVIDER Compute services.
The complete flow for setting up the SEA is:
The CONSUMER chooses a service inside a DDO (the CONSUMER selects a
serviceDefinitionId).The Service Agreement needs to have an associated unique
serviceAgreementIdthat can be generated/provided by the CONSUMER. In the Smart Contracts, thisserviceAgreementIdwill be stored as abytes32. ThisserviceAgreementIdis random and is represented by a 64-character hex string (using the characters 0-9 and a-f). The CONSUMER can generate theserviceAgreementIdusing any kind of implementation providing enough randomness to generate this ID (64-characters hex string).The CONSUMER signs the service details. The signature contains
(templateId, conditionTypes, valuesHashList, timeoutValues, serviceAgreementId).serviceAgreementIdis provided by the CONSUMER and has to be globally unique.- Each ith item in
values_hash_listandtimeoutValueslists corresponds to the ith condition in conditionKeys values_hash_list: a hash of the parameters types and values of each conditiontimeoutValues: list of numbers to specify a timeout value for each condition.
It is used to correlate events and to prevent the PUBLISHER from instantiating multiple Service Agreements from a single request.
- Each ith item in
The CONSUMER initializes the SEA on-chain
(did, serviceAgreementId, serviceDefinitionId, signature, consumerAddress, workflowId).The CONSUMER locks the payment on-chain through the
LockPaymentConditionSmart ContractThe PROVIDER via NODE, receives the
LockPayment.Fulfilledevent where he/she is the provider for this agreementThe PROVIDER grants the execution permissions for the computation on-chain calling the
executeComputeCondition.FullfillmethodThe CONSUMER gets the
executeComputeCondition.Fullfilledevent. When he/she receives the event, can call the NODEserviceEndpointurl added in the DDO to start the execution of the computation workflow. Typically:HTTP POST /api/v1/node/services/execThe NODE receives the CONSUMER request, and calls the
checkPermissionsmethod to validate if the CONSUMER address is granted to execute the service. If user is granted, the NODE triggers the Execute Algorithm action in the infrastructure
Execution phase
During this phase, if and only if the CONSUMER is granted, the CONSUMER can request the start of the Computation in the PUBLISHER infrastructure via NODE.
The complete flow for the Execution phase is:
The NODE after receiving the
executionrequest from CONSUMER, validates the permissions using thecheckPermissionsfunctionIf the CONSUMER is authorized, the NODE resolves the DID of the Workflow associated with the Service Agreement. The workflow includes the details of the pipeline to execute, including the different stages, inputs and outputs.
The NODE starts the Infrastructure Operator (aka OPERATOR SERVICE), to register a new execution in the PROVIDER INFRASTRUCTURE (cloud or on-premise). The NODE sends a "Workflow Registration" HTTP REST request to the OPERATOR SERVICE. This request must include the serviceAgreementId and the Workflow (JSON)
The OPERATOR SERVICE receives a "Workflow Registration" request and:
- Validates in K8s there is no an existing/running workflow with the same
serviceAgreementId - Creates an unique
workflowExecutionIdidentifying a unique execution of the service - Validates the container flavour defined by the CONSUMER in the Workflow is supported in the compute service (DDO)
- Register the workflow in Kubernetes (K8s)
- Validates in K8s there is no an existing/running workflow with the same
All the actions made by the OPERATOR in the infrastructure via K8s MUST include the
serviceAgreementIdandworkflowExecutionIdas tags/labelsFor each stage in the workflow, the OPERATOR orchestrates Orchestration Steps
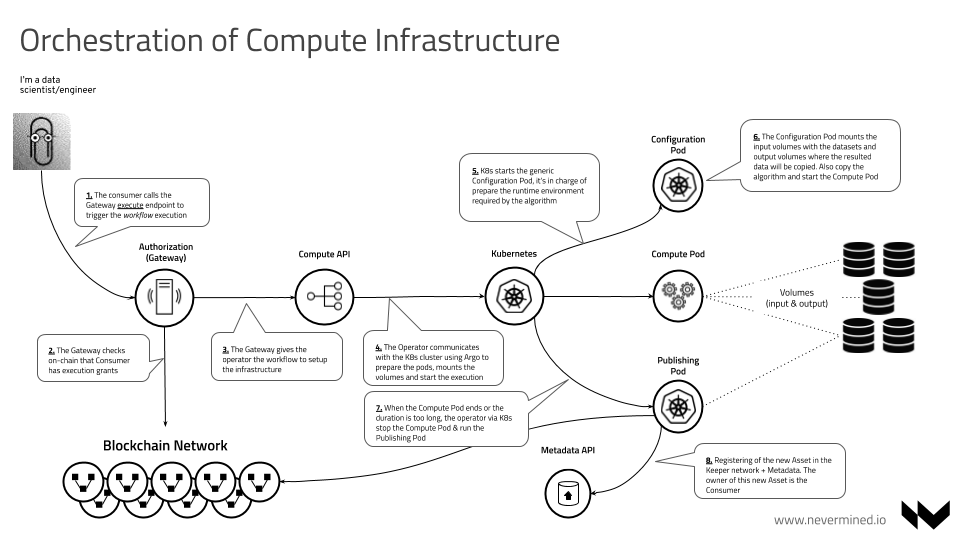
When a new Workflow is created in K8s, the OPERATOR ENGINE fetch the event and execute the following 3 steps:
- Configuration - The OPERATOR ENGINE starts the "Configuration Pod". This pod is in charge of prepare the environment connecting the input volumes to a secure container. Also is in charge of resolving all the DID's involved into the real assets and leave everything ready for further execution. After finishing the pod is stopped.
- Executing - The OPERATOR ENGINE starts the "Compute Pod". This pod is in charge of using the data & algorithm existing in the input volumes, execute the algorithm. The pod only can write data to the output volume. After finishing the execution of the algorithm the pod is stopped.
- Publishing - The OPERATOR ENGINE starts the "Publishing Pod". This pod is in charge of publishing as a new Asset the result generated to the output volume. The ownership of the asset is transferred to the user triggering the computation workflow (typically the data scientist/engineer). After finishing the pod is stopped.
The OPERATOR requests the deletion of all the containers and volumes created in the Kubernetes cluster
The OPERATOR retrieves from the INFRASTRUCTURE (if it's available) a receipt demonstrating the execution of the service
The CONSUMER receives an event including the DID of the new ASSET created
The NODE or any other user may requests the
releasePaymentthrough the SMART CONTRACTS. It commits on-chain the HASH of the receipt ticket collected from the INFRASTRUCTURE provider.
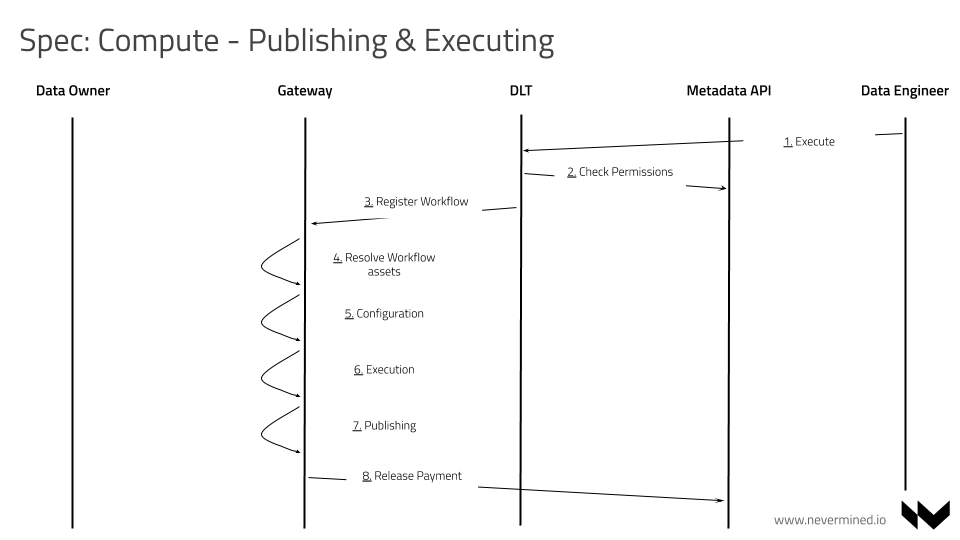
Infrastructure Orchestration
To facilitate the infrastructure orchestration the NODE integrates with Kubernetes (aka K8s) via the OPERATOR component. The OPERATOR allows to abstract the execution of Docker containers with compute services independently of the backend (Amazon, Azure, On-Premise). To support that OPERATOR includes the kubernetes driver allowing to wrap the complete execution including:
- Download of the container images
- Setting up the pods
- Creation of volumes
- Starting and stopping the service
- Retrieval of logs
- Registering the new Asset
- Destroy the pods
The OPERATOR handles 3 types of K8s Pods:
Configuration Podis in charge of resolve the Workflow resources necessary for the execution of the algorithm. It copies the data and algorithm in volumesCompute Podis in charge of run the algorithm. This pod has access in read-only mode to the volumes with the input data and write mode to the output volumePublishing Podis in charge of having all the data and logs generated in the output volume to publish this data in Nevermined as a new asset and handover the ownership to the CONSUMER
Services Provided by the Operator
The services provided by the OPERATOR are:
- Registering a new Workflow execution. Given a
serviceAgreementIdand aWorkflowpayload, starts the execution of the Workflow. It returns aworkflowExecutionIdvalid to track the execution of the Workflow. - Retrieve logs. Given a
serviceAgreementIdandworkflowExecutionIdretrieve the logs associated to that execution - Stop workflow execution. Given a
serviceAgreementIdandworkflowExecutionIdstop/delete all the containers associated with them
Orchestration Steps
The compute scenario requires a complete orchestration of different stages in order to provide an end to end flow. The steps included in this scenario are:
The CONSUMER send a request to the NODE using the compute/exec method in order to trigger the Workflow execution
The NODE receives this request and check on-chain via SMART CONTRACTS if the CONSUMER has grants to execute the Workflow. If the CONSUMER has grants will continue the Infrastructure Operation integration, if not will return an error message.
The NODE calls the Infrastructure Operator (aka OPERATOR SERVICE) giving the Workflow that needs to be executed
The OPERATOR SERVICE communicates with the K8s cluster to register the Workflow in Kubernetes
The OPERATOR ENGINE is registered to the new Workflow Events. When this happens The OPERATOR via K8s starts a generic Configuration Pod. The responsibilities of the configuration pod are:
- Parses the Workflow document
- Resolves the DID resources necessary to run the Workflow
- Pulls the docker image from the Docker registry
- Plugs the different data inputs as volumes in the Compute Pod
- Plugs the output for data and logs as volumes in the Compute Pod
After all the above steps the
Configuration Podmust be stoppedIf the
Configuration Podends successfully the OPERATOR via K8s starts the Compute Pod using the flavour specified by the user in the Workflow definitionThe
Compute Podstarts and runs thecompute-entrypoint.shpart of the algorithm downloaded by theConfiguration PodWhen the
Compute Podends or the duration is too long (timeout), the OPERATOR via K8s stop and delete the Compute PodIf the
Compute Podends, the OPERATOR start a new instance of the Publishing Pod. The responsibilities of the Publishing Pod are:
- List of the Log files generated in the Log volume and copy to the output
- List of the Output data generated in the Output volume
- Generate a new Asset Metadata using the information provided by the CONSUMER
- Register a new Asset in Nevermined including the Output & Log data generated
- Transfer the ownership of the new Asset created to the CONSUMER
- At this point the CONSUMER could get an event of a new created asset where he/she is the owner
Infrastructure Operator
In this SPEC the PROVIDER of a computation service is in charge of defining the requirements to allow the execution of algorithms on top of the data assets. It means only the images specified in the DDO by the publisher with a specific DID and checksum will be allowed to be executed in the Runtime environment.
The OPERATOR SERVICE is in charge of setting up the runtime environment speaking with the infrastructure provider via Kubernetes.
The images defined in the DDO and defined by the PUBLISHER only SHOULD include the minimum libraries specified, it will reduce the risk of executing unexpected software via external libraries. In addition to this, it's recommended that the images running in the runtime environment don't have network connectivity a part of the minimum required to get access to the Assets.
Volumes
The input assets will be added to the runtime environment as read only volumes. The complete paths to the folders where the volumes are mounted will be given to the algorithm as parameters, using the same order of the parameters specified in the Workflow definition. The new derived Asset generated as a result of the execution of the algorithm MUST be written in the output volume. The pods will be destroyed after the execution, so only the data stored in the output or logs volumes should be used.
| Type | Permissions | CLI Parameter |
|---|---|---|
| Input | Read | --input1=/mnt/volume1 --input2=/mnt/volume2 |
| Output | Read, Write | --output=/mnt/output |
| Logs | Read, Write | --logs=/mnt/logs |
Network isolation
The runtime environment doesn't need to have network connectivity to external networks to be executed. To avoid sending the internal information about the data, it's recommended to restrict the output connectivity.